최근 NVIDIA의 실적발표가 있었다. 여기서 CUDA가 핵심동력으로 강조되었다고 기사를 통해서 읽었는데, CUDA가 그렇게 대단한걸까? 경쟁사는 만들 수가 없는걸까? CUDA는 뭐고 교체불가능한 NVIDIA의 핵심동력인지 알아보려고 합니다.
1. CUDA 드라이버는 왜 만들어졌나?

CUDA(Compute Unified Device Architecture)은 NVIDIA가 그래픽 처리만을 위한 GPU (Graphics Processing Unit)를 범용 병렬처리 장치(General Purpose GPU, GPGPU)로 활용하기 위해 고안한 플랫폼입니다. (위키백과)
그 가운데 CUDA 드라이버(Driver)는 GPU 하드웨어와 응용 소프트웨어(개발 코드) 사이를 연결해 주는 핵심 소프트웨어 계층입니다. 예를 들어, 그래픽 카드 드라이버가 디스플레이 출력이나 렌더링을 위해 하드웨어와 소통하는 것처럼, CUDA 드라이버는 GPU 코어에서 범용 연산을 수행할 수 있도록 메모리 할당, 커널 실행, 동기화 등의 명령을 전달하는 역할을 합니다. (docs.vultr.com)
구체적으로 CUDA 드라이버가 처음 만들어진 목적은 다음과 같이 정리할 수 있습니다:
- GPU가 본래 그래픽 렌더링에 최적화된 설계였던 것을, 병렬연산 (parallel compute) 장치로 전환하기 위해.
- CPU 중심 처리 방식이 병렬 연산의 폭발적 증가에 대응하기에 한계가 있었고, GPU의 많은 코어를 활용하려는 시도가 있었음.
- 개발자가 비교적 익숙한 언어(C/C++ 등)로 GPU를 다룰 수 있도록 API/툴킷을 제공하려는 의도.
따라서 CUDA 드라이버는 단순히 그래픽 드라이버가 아니라, 병렬컴퓨팅 가속을 위한 플랫폼의 핵심 기반으로 출발했다고 볼 수 있습니다.
위의 내용을 종합해 보면 AI를 위헤 만들어 졌다기 보다는 게임등 그래픽처리를 유연하면서 직관적(API 제공)이고 그리고 성능(GPU와 직접적인 커뮤니케이션)까지 고려해서 누구나 GPU를 보다 적극적으로 활용할 수 있도록 만들어진 것이 CUDA라고 볼 수 있습니다. CUDA에 대한 관점을 기본적으로 데이터를 동시에(또는 병렬로) 처리할 수 있는 GPU를 활용하 수 있게 해주는 중간계의 관점으로 보면서 조금더 아래로 내려가 보겠습니다.
2. CUDA 드라이버의 원리


이제 조금 더 기술적으로, CUDA 드라이버가 내부적으로 어떻게 작동하는지 핵심 원리를 알아보겠습니다.
(1) 호스트(Host)와 디바이스(Device)의 구분
개발자가 작성한 코드는 일반적으로 CPU에서 실행되며(호스트), 병렬연산을 수행할 대상이 되는 GPU는 디바이스입니다. CUDA 드라이버는 호스트와 디바이스 간의 통신과 제어를 가능하게 만듭니다. (디지털오션)
(2) 메모리 이관 및 실행 명령 전달
호스트 메모리에서 디바이스 메모리로 데이터를 복사하고, 호스트가 “이 커널(kernel)을 이 메모리에서 실행하라”는 명령을 GPU에 전달합니다. 드라이버는 내부적으로 명령 큐(command queue)를 구성하고, 메모리 주소·버퍼·실행 구성 등을 설정합니다. (Stack Overflow)
(3) 병렬 실행 단위 구성: 스레드/블록/그리드
하나의 커널 함수는 수천 개 이상의 스레드(thread)로 실행되며, 이 스레드들은 블록(block)이라는 그룹으로 묶이고, 블록들은 그리드(grid)를 구성합니다. 각 스레드는 GPU 코어상에서 동시다발적으로 실행되며, 공유 메모리(shared memory), 레지스터(register), 글로벌 메모리(global memory) 등 메모리 계층 구조를 갖습니다. (디지털오션)
(4) 드라이버 API vs 런타임 API 역할
CUDA에는 낮은 수준의 ‘Driver API’와 더 사용하기 쉬운 ‘Runtime API’가 존재합니다. 드라이버 API는 GPU 디바이스 초기화·메모리 할당·디바이스 속성 확인 등을 직접 제어할 수 있는 반면, 런타임 API는 더 추상화되어 개발 편의성이 높습니다. (위키백과)
따라서 요약하면,
호스트(개발 코드) → CUDA 드라이버(API) → GPU(디바이스) 메모리/명령 큐 → 수많은 병렬 스레드 실행
이 흐름이 CUDA 드라이버가 작동하는 기본 메커니즘입니다.
(수정보강: 드라이버는 실제 GPU 하드웨어와 응용 프로그램 사이 물리·논리 인터페이스이며, 이전 초안에서 드라이버 기능을 조금 간소화했던 점을 보완했습니다.)
3. AI 시대에서 CUDA 드라이버가 선택받은 이유
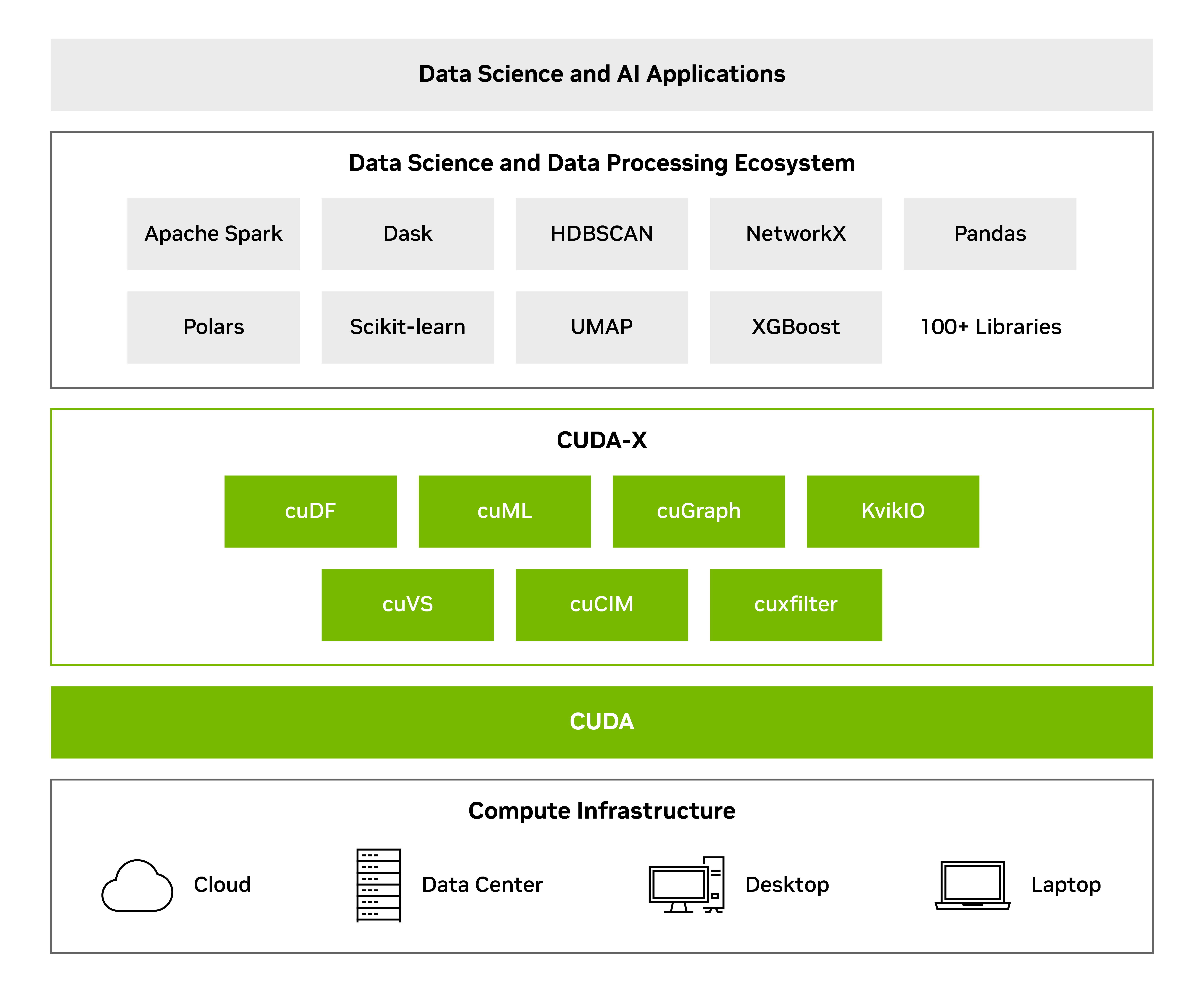

최근 AI 시대가 도래하면서 CUDA 드라이버 및 그 생태계가 더욱 주목받고 있습니다. 그 이유는 아래와 같습니다.
- 병렬연산량의 급증 : AI 훈련 및 추론, 특히 대형 언어 모델이나 이미지 / 영상 처리 같은 워크로드에서는 수십억 ~ 수조 개의 연산이 병렬로 처리되어야 합니다. GPU는 원래 그래픽 처리를 위해 수많은 코어를 갖춘 구조이고, CUDA는 이를 범용 연산으로 활용하도록 만든 플랫폼입니다. (디지털오션)
- 메모리·데이터 이동 최적화 : CUDA 드라이버는 GPU 메모리와 호스트 메모리 간 데이터 이동, 공유 메모리/레지스터/글로벌 메모리 등의 계층 구조 제어를 통해 병목을 줄이는 설계를 지원합니다. 이를 통해 AI 워크로드에서 중요한 성능 향상이 가능해졌습니다. (출처: CUDA 메모리 구조 설명) (디지털오션)
- 생태계 및 라이브러리 지원 : CUDA를 중심으로 수백 개 이상의 GPU 가속 라이브러리, 프레임워크, 개발 툴킷이 구축되어 왔습니다. 개발자나 기업 입장에서는 “이미 잘 갖춰진 환경”이 큰 장점입니다. (NVIDIA Docs)
- 하드웨어-소프트웨어 통합 : 예컨대 NVIDIA의 Tensor Core 같은 AI 특화 연산 유닛과 CUDA 드라이버 / 툴킷이 밀접히 연결되면서, AI 모델을 효율적으로 훈련하고 배포할 수 있는 환경이 마련돼 있습니다.
- 네트워크 효과(Network Effect) : 더 많은 개발자와 기업이 CUDA 생태계를 사용하니, 더 많은 라이브러리와 툴이 만들어지고, 다시 사용자들이 몰리는 선순환이 형성되었습니다. 따라서 “GPU 컴퓨팅 = CUDA”라는 인식이 자리잡았습니다.
종합하면, AI 시대에서 CUDA 드라이버는 기존 GPU 하드웨어를 범용 가속기로 전환하고, AI 워크로드에 적합한 연산·메모리 관리·생태계를 제공함으로써 선택받았다고 볼 수 있습니다.
물론, AMD나 INTEL도 돌릴 수 있습니다. 문제는 H/W Driver를 직접 구현하고 Adoption 해서 Python library 들이 인식할 수 있게 해줘야하는 번거로움 그리고 안정성에 대한 보장/담보할 수 없는 것이 문제입니다.
결국 AI 연산을 위해 병렬처리를 많이 해야하는데, Python library 들이 직접 H/W Driver를 implement 해서 사용하는 것이 아니, CUDA는 그 중간에서 Python library와 GPU Device 간 중간역활을 아주아주 잘 하면서 AI 시대에 NVIDIA의 CUDA는 중요한 역활을 하게되었고, 지금은 거의 모든 Python library 들이 CUDA의 API 등을 활용해서 병렬 처리를 하고 있습니다.
4. 대항마는 없는가? 그리고 과연 대체될 수 없는가?
이제 한 걸음 물러나서 “CUDA 드라이버가 절대적인가? 대체 가능한가?”를 살펴보겠습니다.


- 현재 가장 대표적인 대항마로는 ROCm(Radeon Open Compute, AMD)가 있으며, 이는 오픈소스 기반 GPU 계산 스택으로, 드라이버·툴·API를 포함합니다.
- 또 다른 시도인 oneAPI(Intel 주도) 같은 하드웨어 아키텍처 독립형 표준도 존재합니다.
대체될 수 없는가?
강점 측면 → CUDA는 생태계가 잘 갖춰져 있고 하드웨어-소프트웨어 통합이 깊다는 점에서 매우 강력합니다.
한계 및 가능성 측면 → 하지만 다음과 같은 조건이 갖춰지면 대체 혹은 경쟁 가능성도 있습니다: - 다른 플랫폼이 충분한 성능을 제공할 것
- 호환성(라이브러리·툴·개발자 커뮤니티)이 확보될 것
- 개발 비용이나 벤더락-인(Vendor lock-in) 이슈가 완화될 것과 실제로 AMD 등 업체가 그 방향으로 움직이고 있는 것이 사실입니다.
결론적으로 “현재로서는 CUDA 드라이버가 시장-생태계 측면에서 우위에 있다”라고 볼 수 있으나, “완전히 대체 불가능하다”고 단정하기는 어렵습니다. 다만 대체되려면 극히 높은 생태계 전환 장벽이 존재한다는 점은 유의해야 합니다. 이렇듯 생태계의 견고성을 알아서 였을까요?? CUDA를 License화 해서 GPU를 활용하기 위한 CUDA를 사용하려면 구독료로 어마어마한 돈을 내야하는 치명적인 담정이 생겨버렸습니다. 물론 NVIDIA는 하드웨어 안팔고도 다달이 들어오는 라이선스 비용이 참으로 고맙겠지만 너무 비싼것도 사실입니다.
5. NVIDIA의 다음은?
NVIDIA는 2019년에 Mellanox를 인수합병하고 Mellanox의 InfiniBand라는 기술을 이용해서 초고속 대용량 (거의 하나처럼 동작하는) GPU팜을 운용할 수 있는 솔루션을 제안했습니다(전남대였나? PoC 및 설치했던 기억이).

워낙에 빠르고 대량의 GPU를 거의 하나와 같이 묶어서 사용할 수 있도록 해주니 연구용으로 최고의 솔루션이라 보지만 가격이 만만치 않고, 또한 기술의 보안도도 높아서 전문 엔지니어가 없이 세팅을 못한다고 보시면 됩니다. 세팅을 잘못하면 오히려 비싼 가격대비 효율이 굉장히 떨어질 수 있다고 하더라구요(이건 실제 미팅에서 주고받은 그 때의 기억을 담았습니다).
당시만해도 국내에 전문가가 없어 본사에서였나 Asida Header 였나에서 지원을 받아 설치했었던 기억이 있습니다. 여튼, NVIDIA는 infiniband를 활용할 수있는 LinkX를 내어놓고 CUDA 또한 LinkX를 사용할 수 있도록 하면서 넘사벽 생태계가 만들어 졌다고 볼 수 있습니다(이러니 수요조절 하면서 마진율이 70%가까이 된는거지 않을까?? 비싸게 비싸게;;;;).
5. 마무리 / 결론
- CUDA 드라이버는 GPU를 단순한 그래픽 처리 장치에서 범용 병렬처리 장치로 전환하기 위해 등장
- 내부적으로는 호스트-디바이스 구조, 메모리 이관, 스레드/블록/그리드 구성 등의 메커니즘을 통해 작동
- AI 시대에는 CUDA는 대량 병렬연산 + 메모리 최적화 + 풍부한 생태계에 중간자 적역활을 (아주아주)잘 한 덕분에 선택받음
- 경쟁 기술(ROCm, oneAPI 등)은 존재하지만, 생태계 전환까지는 적잖은 시간이 걸릴 것이며 현재로선 CUDA가 우위에 있다는 결론입니다.
- NVIDIA는 Mellanox 인수로 다음의 다음까지 준배 둔게 아닐까 함.